import numpy as npimport scipy as spimport pandas as pdimport matplotlib.pyplot as pltimport statsmodels.formula.api as smfplt.style.use("fivethirtyeight")import pymc as pmimport seaborn as snsimport arviz as azfrom statsmodels.graphics.tsaplots import plot_acf
WARNING (pytensor.tensor.blas): Using NumPy C-API based implementation for BLAS functions.
This is a simple linear regression model as in every textbooks \[
Y_i=\beta_1+\beta_2X_i+u_i\qquad i = 1, 2, ..., n
\] where \(Y\) is dependent variable, \(X\) is independent variable and \(u\) is disturbance term. \(\beta_1\) and \(\beta_2\) are unknown parameters that we are aiming to estimate by feeding the data in the model.
Following Gauss-Markov assumptions, \[
E(Y|X_i) = {\beta}_1 + {\beta}_2X_i\\
Y_{i} \sim \mathrm{N}\left({\beta_{1}}+{\beta_{2}}X_{i}, \sigma^{2}\right)
\] Similarly, the precision parameter \(h\) is defined as the inverse of variance \(\sigma^2\), i.e. \(h=\frac{1}{\sigma^2}\).
The Priors
Each of these three parameters, i.e. \(\beta_1\), \(\beta_2\) and \(h\) will be estimated, therefore each of them have their own prior elicitation which means defining a prior with all proper knowledge available. For demonstration purpose, we define \(\beta\) priors as normal distributions, however in many case, \(\beta\) and \(h\) are modeled together with a joint distribution.
However the \(h\) can’t be negative, therefore a Gamma distribution would be appropriate. The posterior of \(h\) will follow a Gamma distribution too due to Gamma-Normal conjugate. \[
P(h)=\frac{\theta_{0}^{\alpha_{0}} h^{\alpha_{0}-1} e^{-\theta_{0} h}}{\Gamma\left(\alpha_{0}\right)} \quad 0 \leq h \leq \infty
\]
Likelihood Function
With normality assumption, likelihood of \(Y\) is \[
\mathcal{L}\left(Y | \mu_{i}, \sigma^{2}\right)=\prod_{i=1}^n\frac{1}{\sigma \sqrt{2 \pi}} \exp{\left(-\frac{1}{2}\left(\frac{Y_i-\mu_i}{\sigma}\right)^{2}\right)}
\]
Equivalently, replace \(\sigma\) by \(h\) and rewrite the function into summation \[
\mathcal{L}\left(Y | \mu_{i}, h\right)=(2 \pi)^{-\frac{n}{2}} h^{\frac{n}{2}} \exp{\left(-\frac{1}{2} h \sum_{i=1}^n\left(Y_{i}-\mu_{i}\right)^{2}\right)}
\]
Replace \(\mu_i\) by \({\beta}_1 + {\beta}_2X_i\), note how we have change the notation of parameters \[
\mathcal{L}\left(Y | \beta_1, \beta_2, h\right)=(2 \pi)^{-\frac{n}{2}} h^{\frac{n}{2}} \exp{\left(-\frac{1}{2} h \sum_{i=1}^n\left(Y_{i}-({\beta}_1 + {\beta}_2X_i)\right)^{2}\right)}
\]
The likelihood function are the same for \(\beta_1\), \(\beta_2\) and \(h\). \[
\mathcal{L}\left(Y | \beta_1\right)=\mathcal{L}\left(Y | \beta_2\right)=\mathcal{L}\left(Y | h\right)=(2 \pi)^{-\frac{n}{2}} h^{\frac{n}{2}} \exp{\left(-\frac{1}{2} h \sum_{i=1}^n\left(Y_{i}-({\beta}_1 + {\beta}_2X_i)\right)^{2}\right)}
\]
The Posteriors
Be careful about the notation, \(h_1\) is the precision of \(\beta_1\) which is a variable rather than a constant viewed in frequentists.
To start from \(\beta_1\)\[
P\left(\beta_{1}\right) \times P\left(Y\mid \beta_{1}\right)=(2 \pi)^{-\frac{1}{2}} h_{1}^{\frac{1}{2}} \exp\left({-\frac{h_{1}}{2}\left(\beta_{1}-\mu_{1}\right)^{2}}\right) \times (2 \pi)^{-\frac{n}{2}} h^{\frac{n}{2}} \exp{\left(-\frac{1}{2} h \sum_{i=1}^n\left(Y_{i}-({\beta}_1 + {\beta}_2X_i)\right)^{2}\right)}
\]
Let’s focus on exponential term for now, expand the brackets \[\begin{align}
&\exp{\left(-\frac{1}{2} h_{1}\left(\beta_{1}-\mu_{1}\right)^{2}-\frac{1}{2} h \sum_{i=1}^n\left(Y_{i}-\beta_{1}-\beta_{2} X_{i}\right)^{2}\right)}\\
&= \exp{\left[-\frac{1}{2} h_{1}\left(\beta_{1}^{2}-2 \beta_{1} \mu_{1}+\mu_{1}^{2}\right)-\frac{1}{2} h\left(n \beta_{1}^{2}-2 \beta_{1} \sum_{i=1}^n\left(Y_{i}-\beta_{2} X_{i}\right)+\sum_{i=1}^n\left(Y_{i}-\beta_{2} X_{i}\right)^{2}\right)\right]}\\
&=\exp{\left[-\frac{1}{2}\left(h_{1}+n h\right) \beta_{1}^{2}-\frac{1}{2}\left[-2 h_{1} \mu_{1}-2 h \sum_{i=1}^n\left(Y_{i}-\beta_{2} X_{i}\right)\right] \beta_{1}-\frac{1}{2} h_{1} \mu_{1}^{2}-\frac{1}{2} h \sum_{i=1}^n\left(Y_{i}-\beta_{2} X_{i}\right)^{2}\right]}\\
&=\exp{\left[-\frac{1}{2}\left(h_{1}+n h\right) \beta_{1}^{2}+\left[h_{1} \mu_{1}+h \sum_{i=1}^n\left(Y_{i}-\beta_{2} X_{i}\right)\right] \beta_{1}+\frac{-\frac{1}{2}\left[h_{1} \mu_{1}+h \sum_{i=1}^n\left(Y_{i}-\beta_{2} X_{i}\right)\right]^{2}}{h_{1}+n h}-\frac{-\frac{1}{2}\left[h_{1} \mu_{1}+h \sum_{i=1}^n\left(Y_{i}-\beta_{2} X_{i}\right)\right]^{2}}{h_{1}+n h}-\frac{1}{2} h_{1} \mu_{1}^{2}-\frac{1}{2} h \sum_{i=1}^n\left(Y_{i}-\beta_{2} X_{i}\right)^{2}\right]}\\
\end{align}\] The first three terms can be combined and the rest are free of \(\beta_1\), which will be denoted as \(C\).
The denominator is equal to \(1\), which leaves us \[
P\left(\beta_{1} | Y\right)=(2\pi)^{-\frac{1}{2}}(h_1+nr)^{\frac{1}{2}}\exp{\left[-\frac{1}{2}\left(h_{1}+n h\right)\left[\beta_{1}-\frac{\left(h_{1} \mu_{1}+h \sum_{i=1}^n\left(Y_{i}-\beta_{2} X_{i}\right)\right)}{h_{1}+n h}\qquad\right]^{2}\right]}
\] Compare with the prior \[
P(\beta_1)=(2 \pi)^{-\frac{1}{2}} h_1^{\frac{1}{2}} \exp{\left(-\frac{1}{2} h_1 \left(\beta_1-\mu_1\right)^{2}\right)}
\]
The posterior hyperparameters of \(\beta_1\) are \[
\begin{gathered}
\mu_{\text {1posterior }}=\frac{h_{1} \mu_{1}+h \sum_{i=1}^n\left(Y_{i}-\beta_{2} X_{i}\right)}{h_{1}+n h} \\
h_{\text {1posterior }}=h_{1}+n h
\end{gathered}
\]
The derivation of posterior for \(\beta_2\) are very, will not be reproduced here \[
\begin{gathered}
\mu_{2 \text { posterior }}=\frac{h_{2} \mu_{2}+h \sum_{i=1}^n X_{i}\left(Y_{i}-\beta_{1}\right)}{h_{2}+h \sum_{i=1}^n X_{i}^{2}} \\
h_{2 \text { posterior }}=h_{2}+h \sum_{i=1}^n X_{i}^{2}
\end{gathered}
\]
We will derive the posterior of \(h\), prior multiply by likelihood equals \[
P(h) P(Y | h)=\frac{\beta_{0}^{\alpha_{0}} h^{\alpha_{0}-1} e^{-\beta_{0} h}}{\Gamma\left(\alpha_{0}\right)} *(2 \pi)^{-\frac{n}{2}} h^{\frac{n}{2}} \exp{\left[-\frac{1}{2} h \Sigma\left(y_{i}-\left(b_{0}-b_{1} x_{i}\right)\right)^{2}\right]}
\]
However, please note that there is no need to memorize any of these derivations, they are here as a reference. We don’t run regression based on these formulae.
A Simulated Example
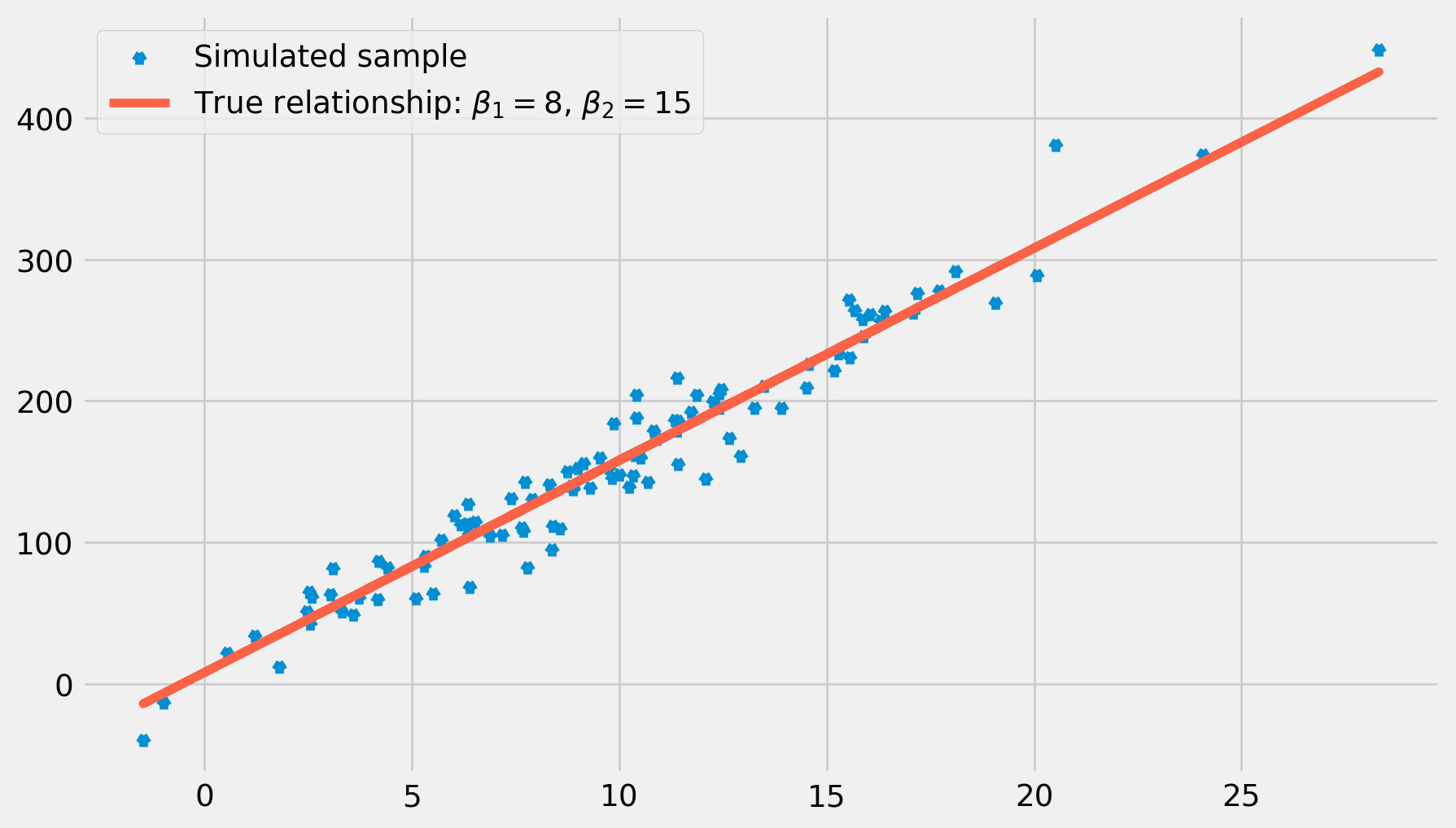
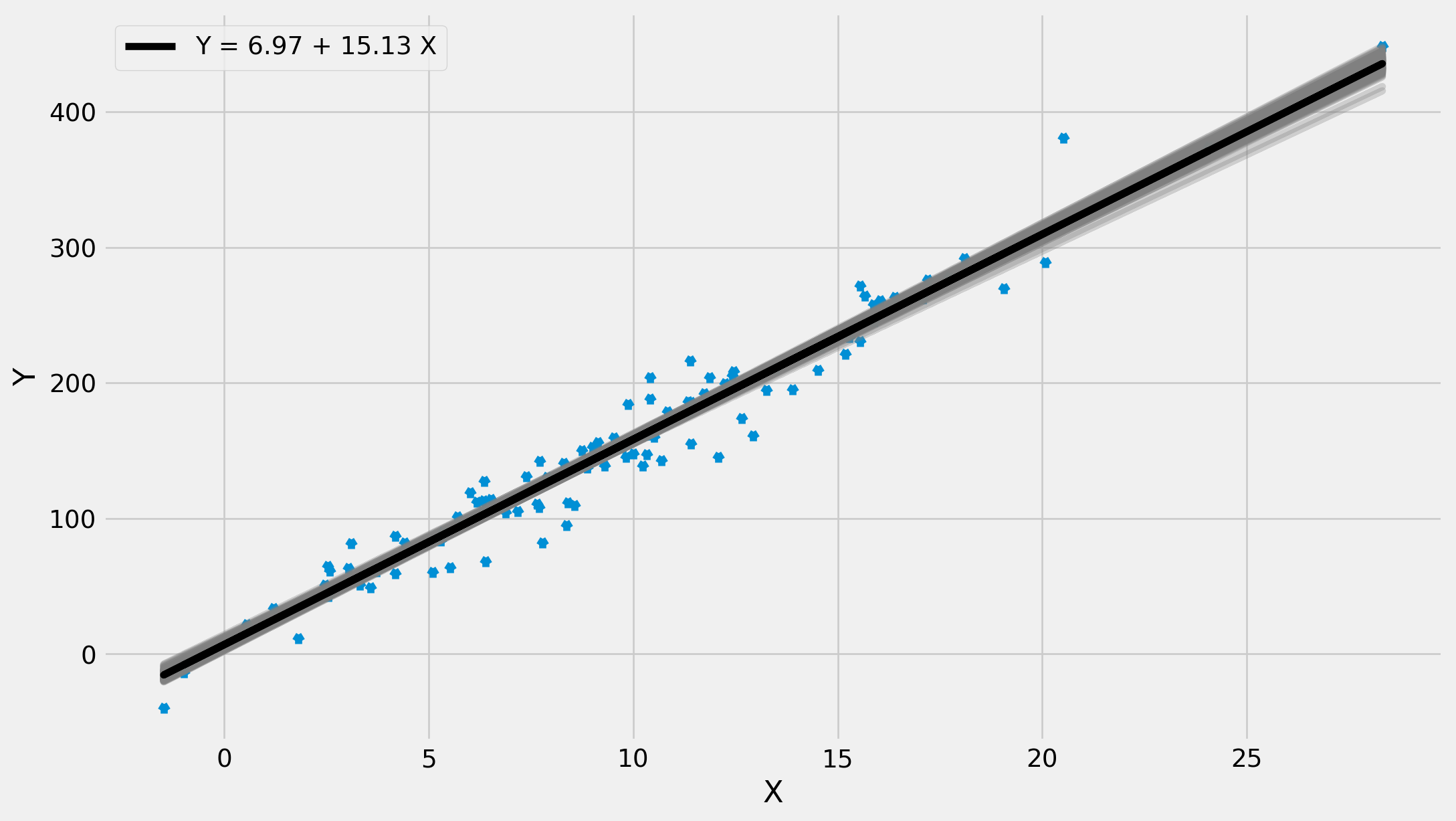
Generate the sample with the real relationship \[
Y_i = 8+15X_i+u_i
\]
/home/runner/.cache/pypoetry/virtualenvs/workspace-env-xqASYfE0-py3.12/lib/python3.12/site-packages/pymc/step_metho
ds/metropolis.py:285: RuntimeWarning:
overflow encountered in exp
Sampling 2 chains for 1_000 tune and 2_000 draw iterations (2_000 + 4_000 draws total) took 3 seconds.
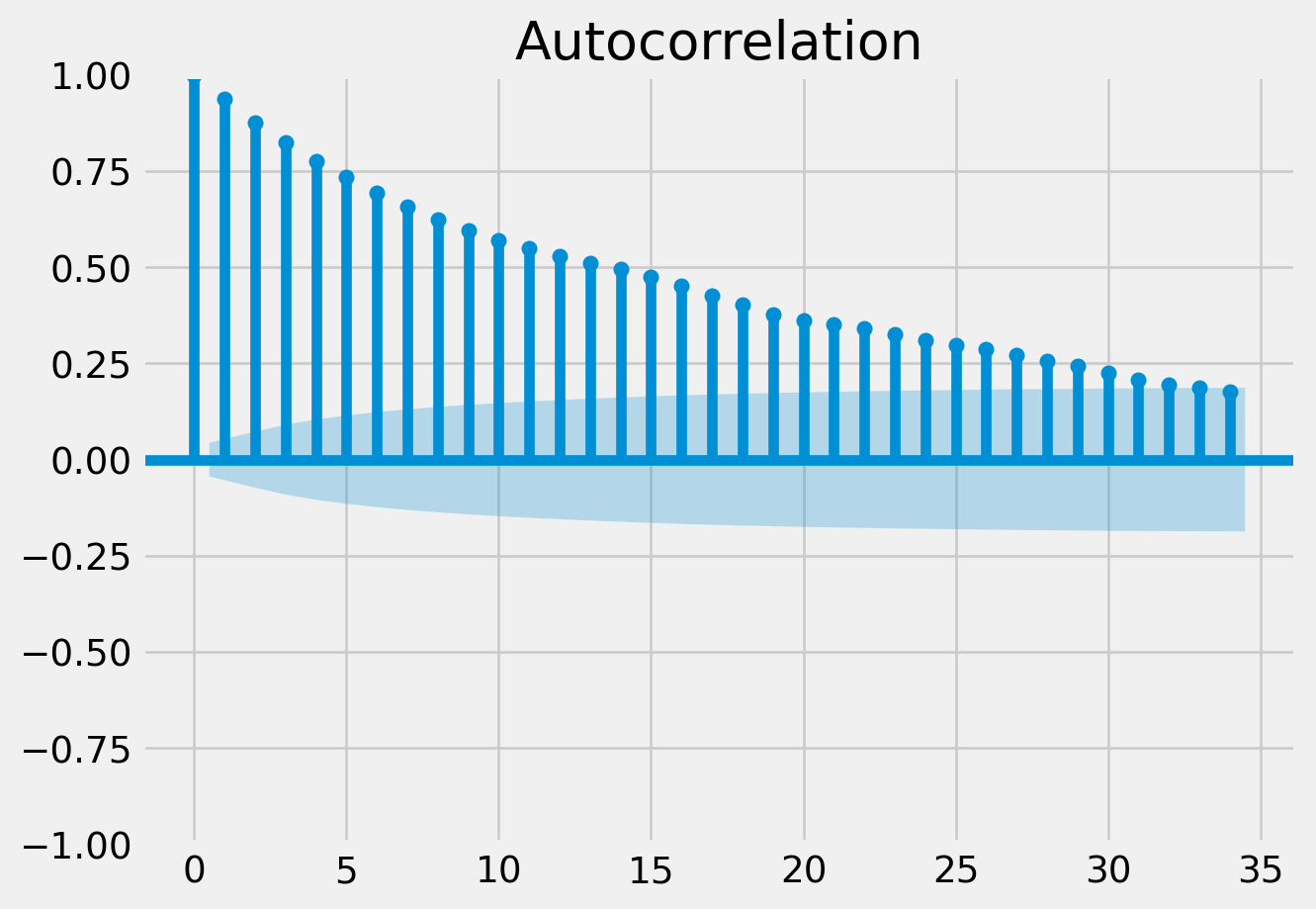
We recommend running at least 4 chains for robust computation of convergence diagnostics
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
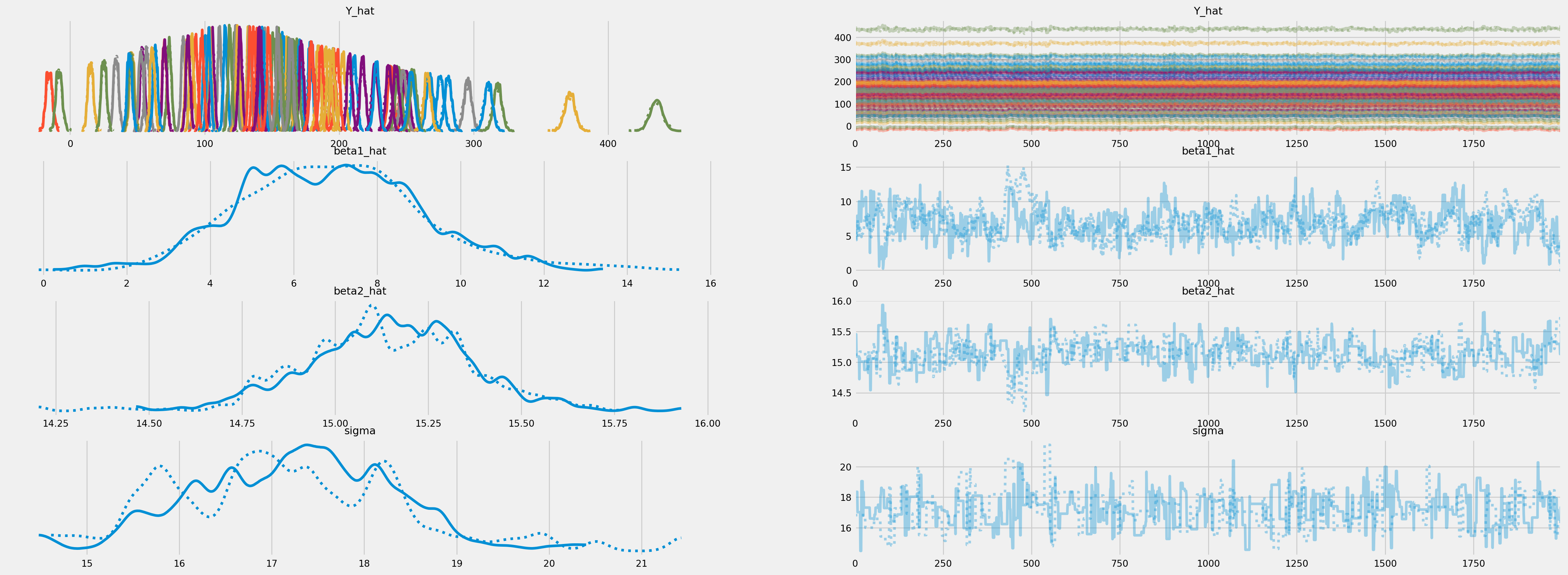
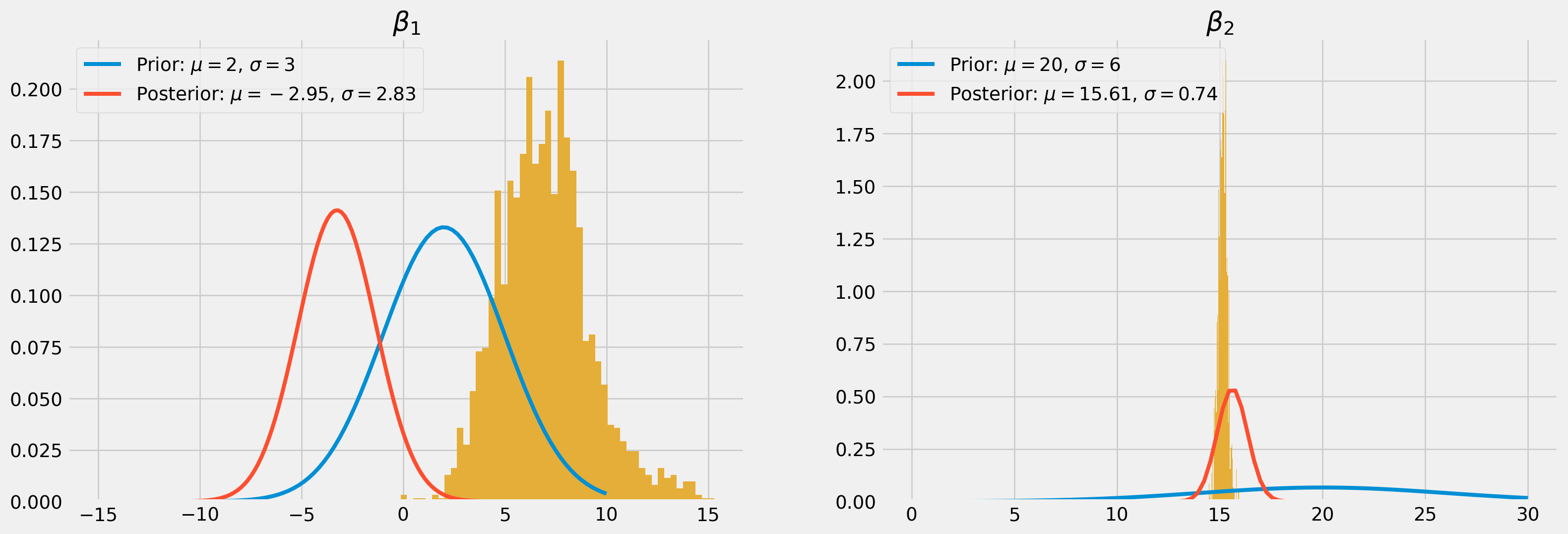
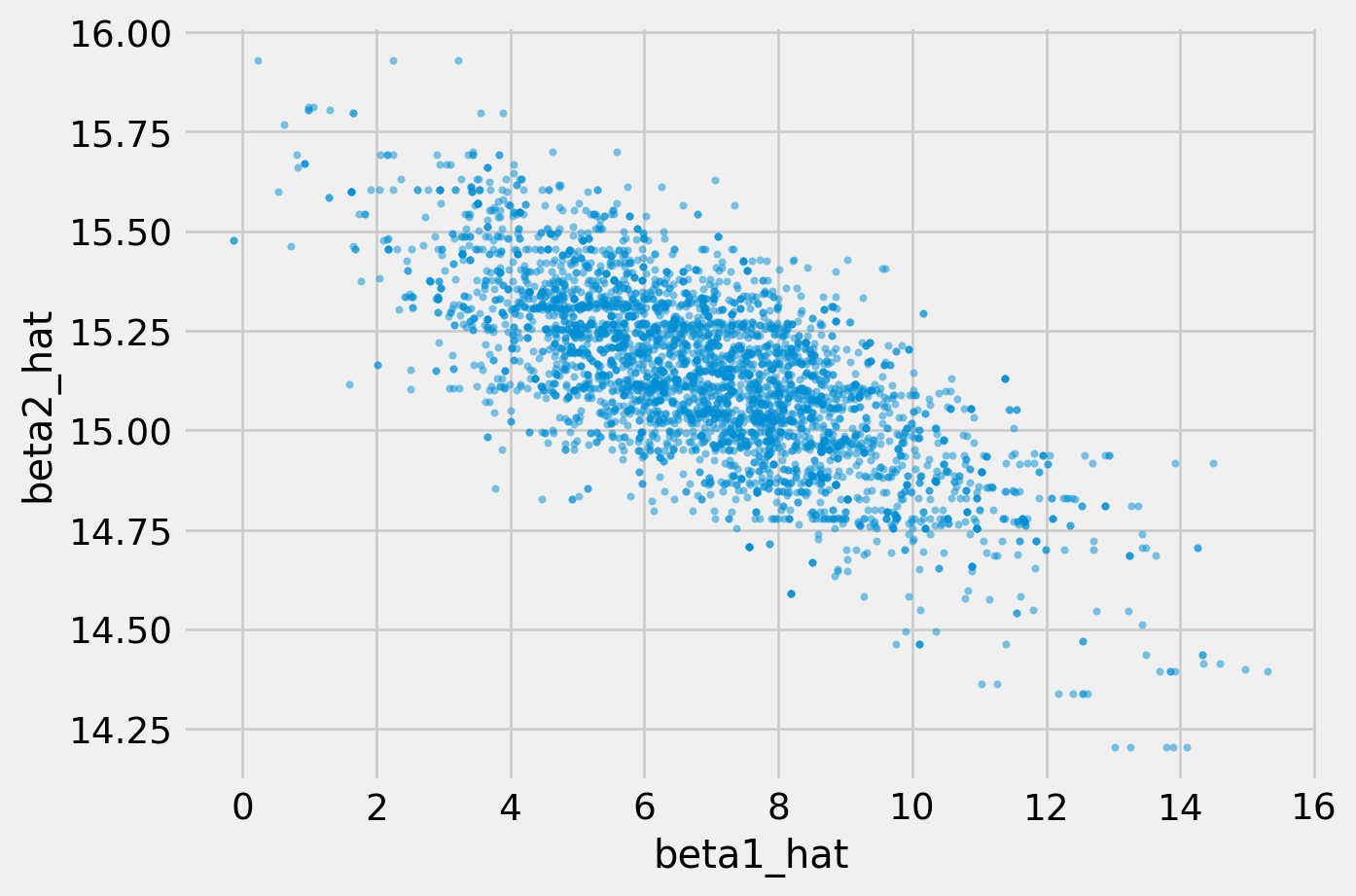
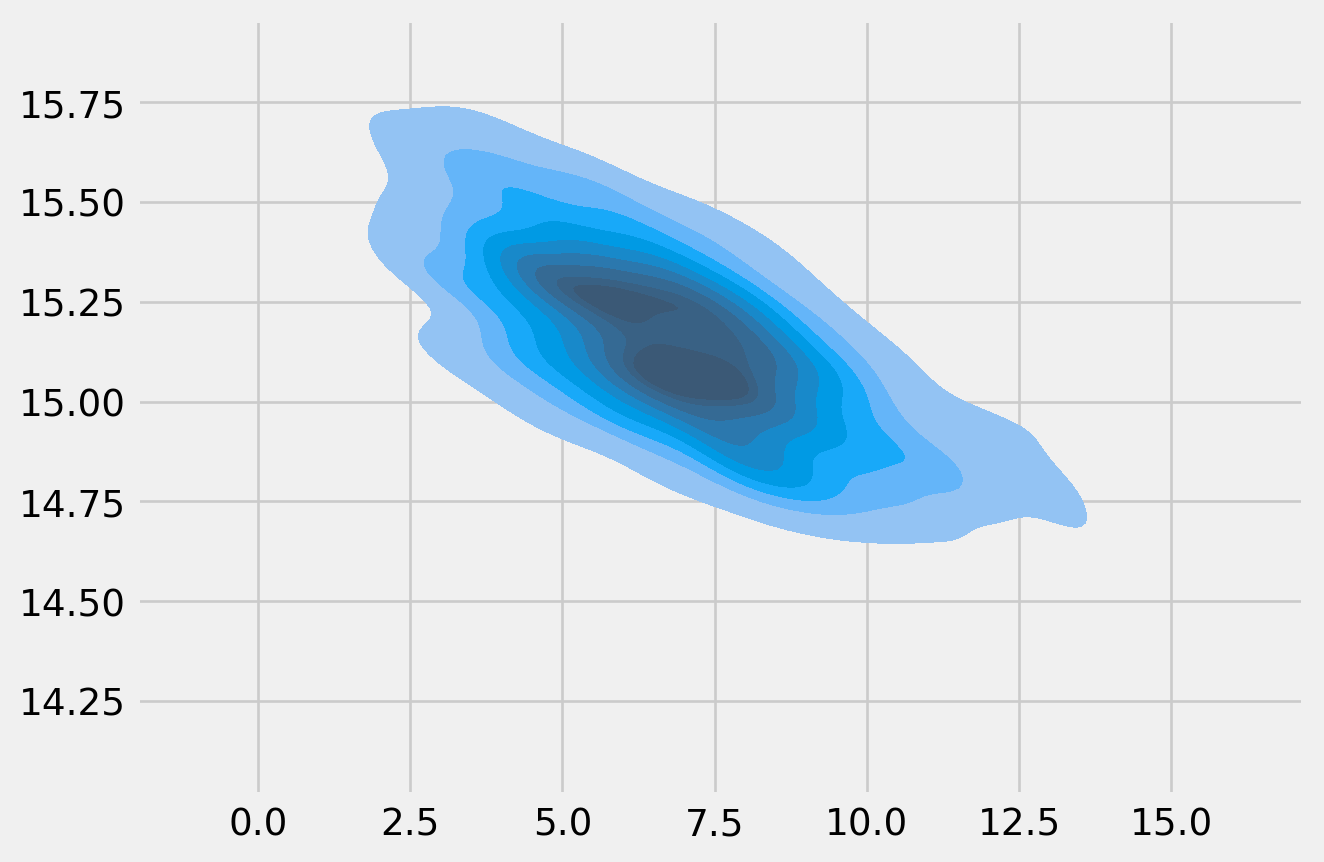
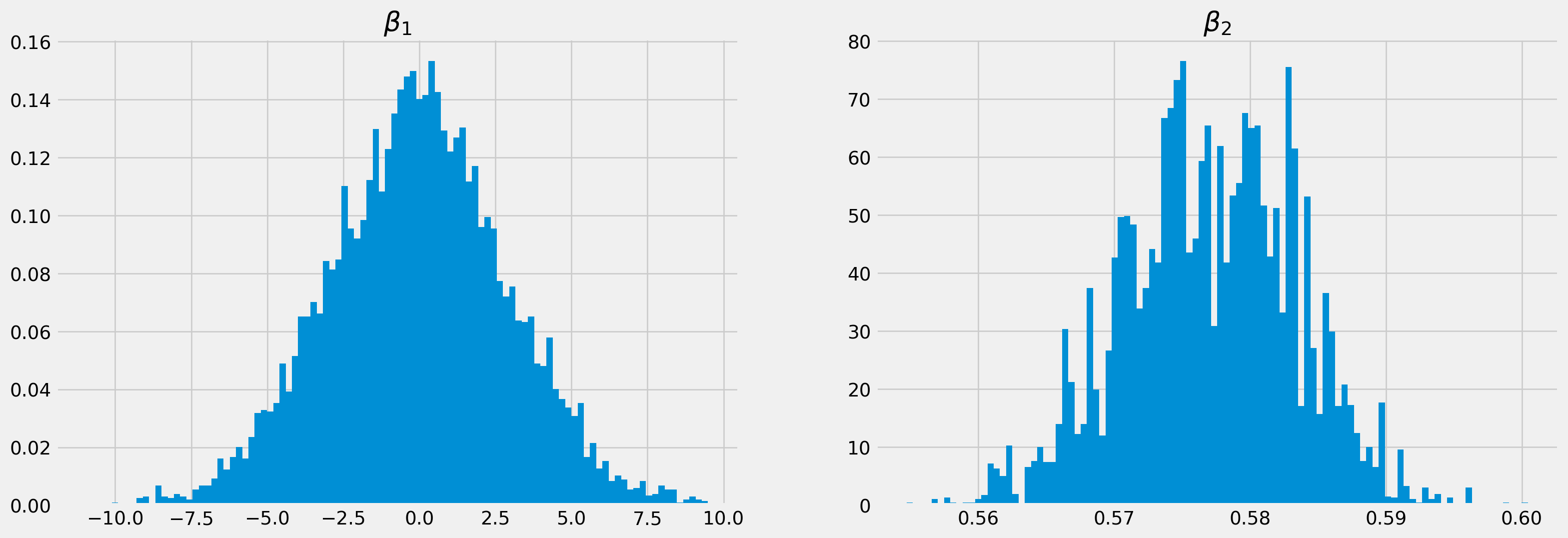
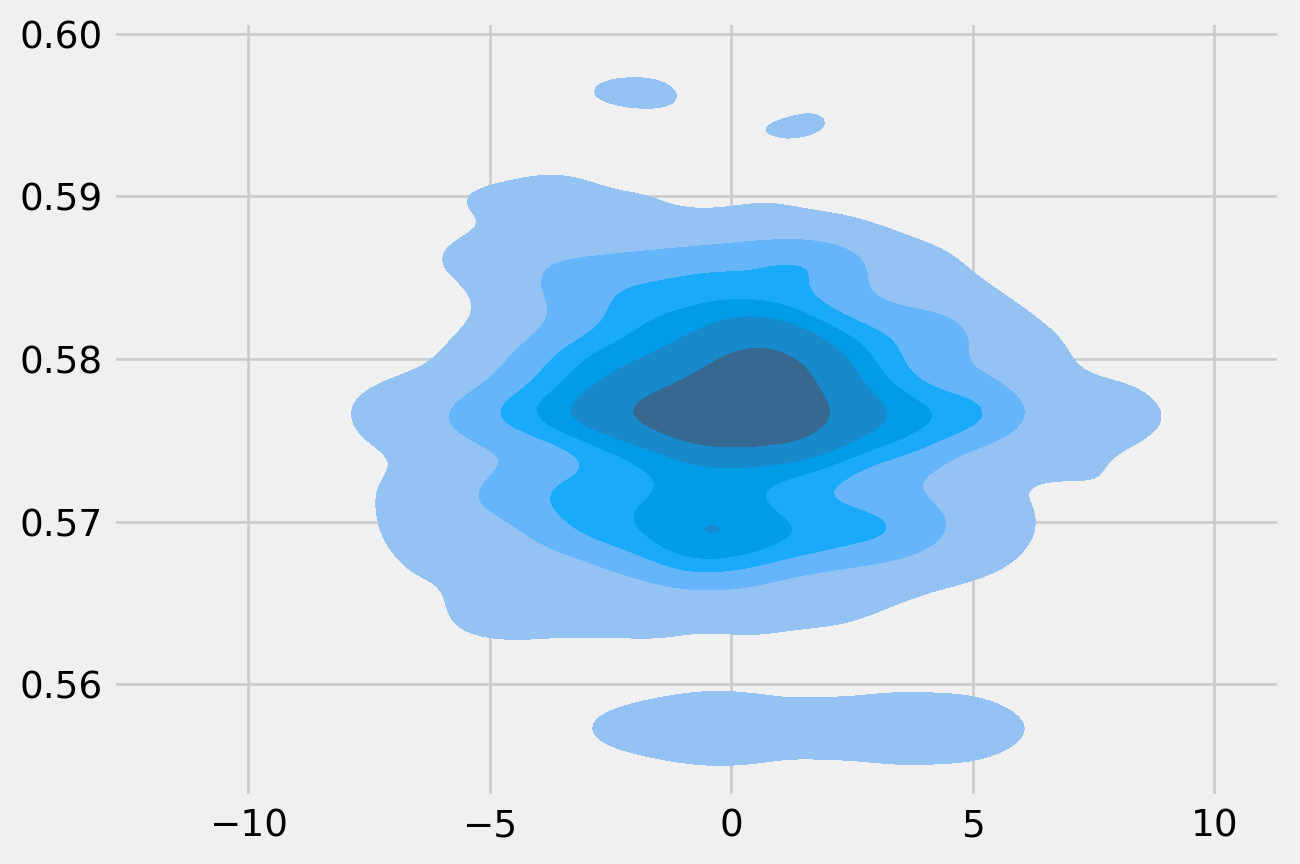
By plotting the scatter plot of simulated \(\beta_1\) and \(\beta_2\), we actually can see the joint of posterior of them, which is by default a ellipsoid.
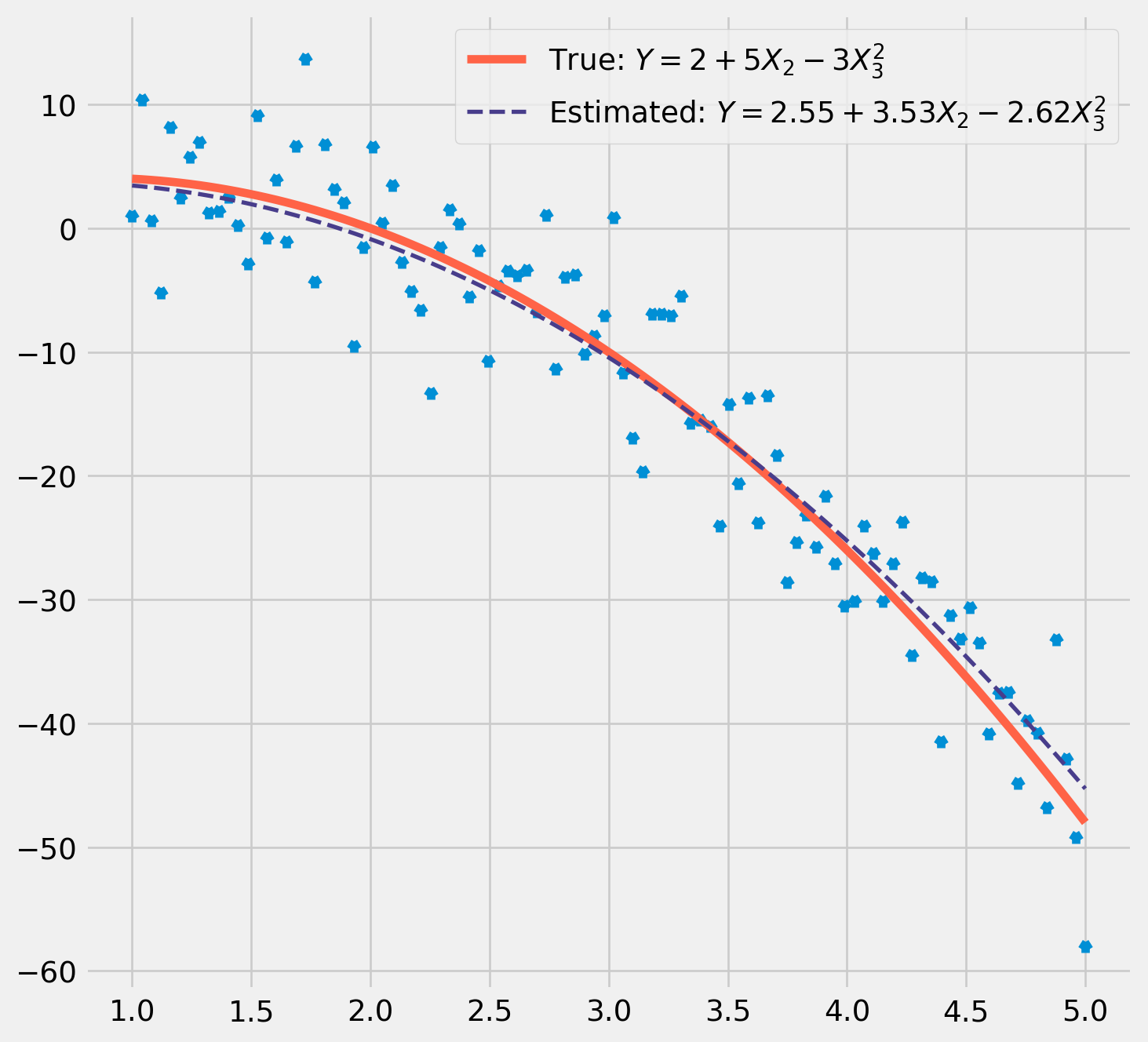
The model to fit the data ill be exactly as we derived above, i.e. \[
Y_i=\beta_1+\beta_2X_i+u_i\qquad i = 1, 2, ..., n
\]
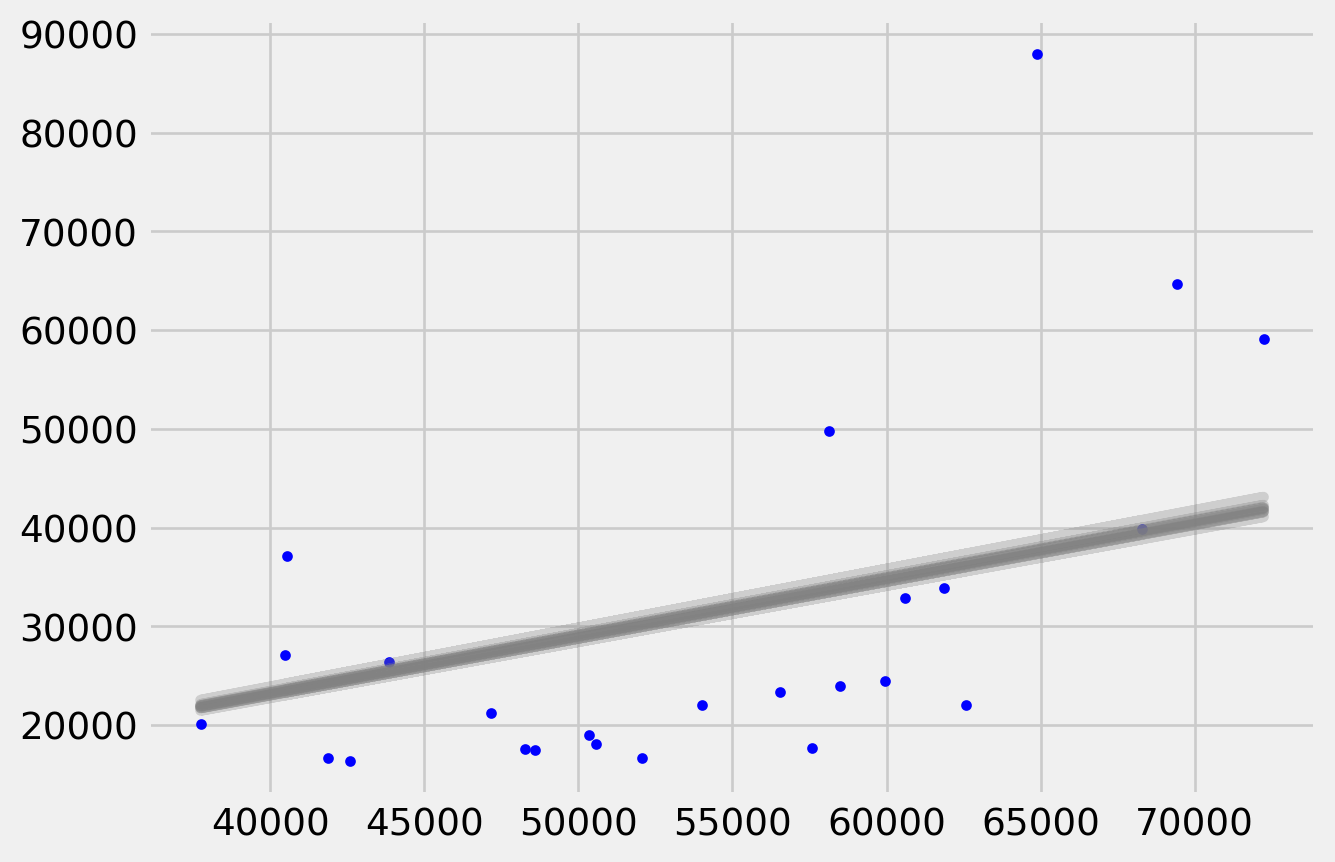
This simple model aims to explain the influence of salary on apartment price per square meter. The \(\beta_1\) doesn’t have much meaning in the model, literally it means the apartment price when salary equals \(0\). However \(\beta_2\) has a concrete meaning that how much apartment price can raise based on every one yuan increase in average salary.
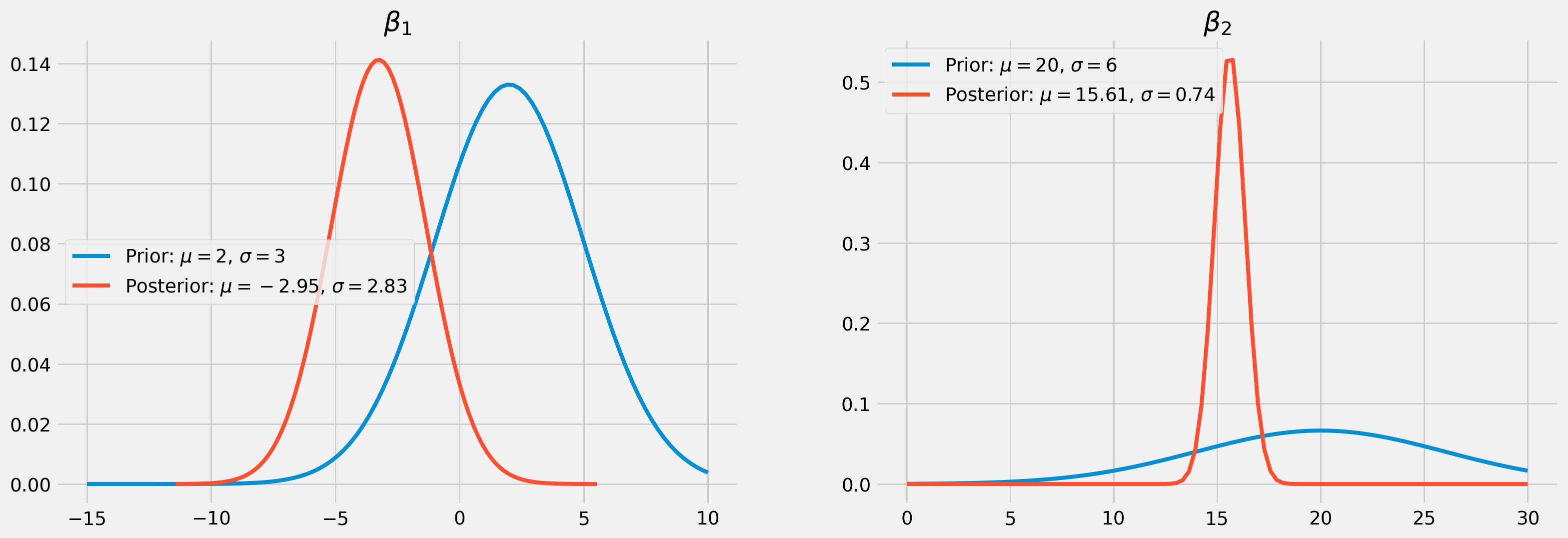
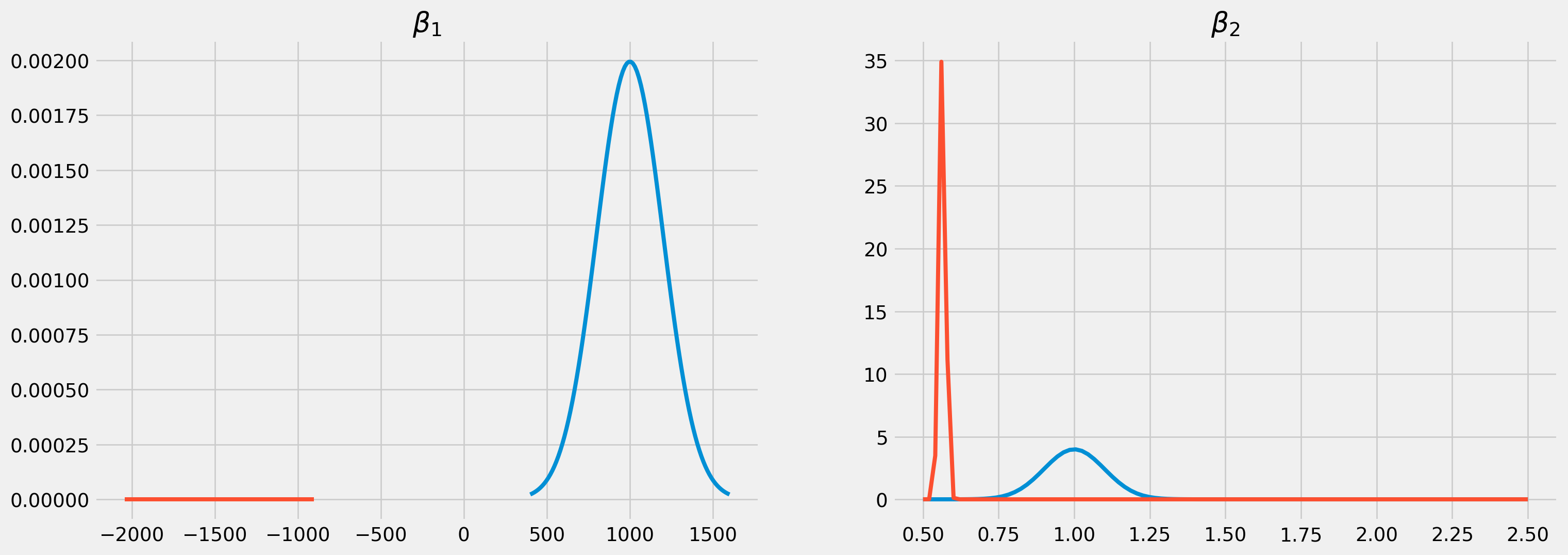
We can choose to elicit priors’ hyperparameters for \(\beta_1\) and \(\beta_2\) as \[
\mu_1 = 1000\\
\sigma_1 = 200 \qquad h_1 = \frac{1}{\sigma_1^2}\\
\mu_2 = 1.5\\
\sigma_2 = .3 \qquad h_2 = \frac{1}{\sigma_2^2}\\
\]
/home/runner/.cache/pypoetry/virtualenvs/workspace-env-xqASYfE0-py3.12/lib/python3.12/site-packages/pymc/step_metho
ds/metropolis.py:285: RuntimeWarning:
overflow encountered in exp
Sampling 2 chains for 1_000 tune and 10_000 draw iterations (2_000 + 20_000 draws total) took 11 seconds.
We recommend running at least 4 chains for robust computation of convergence diagnostics
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
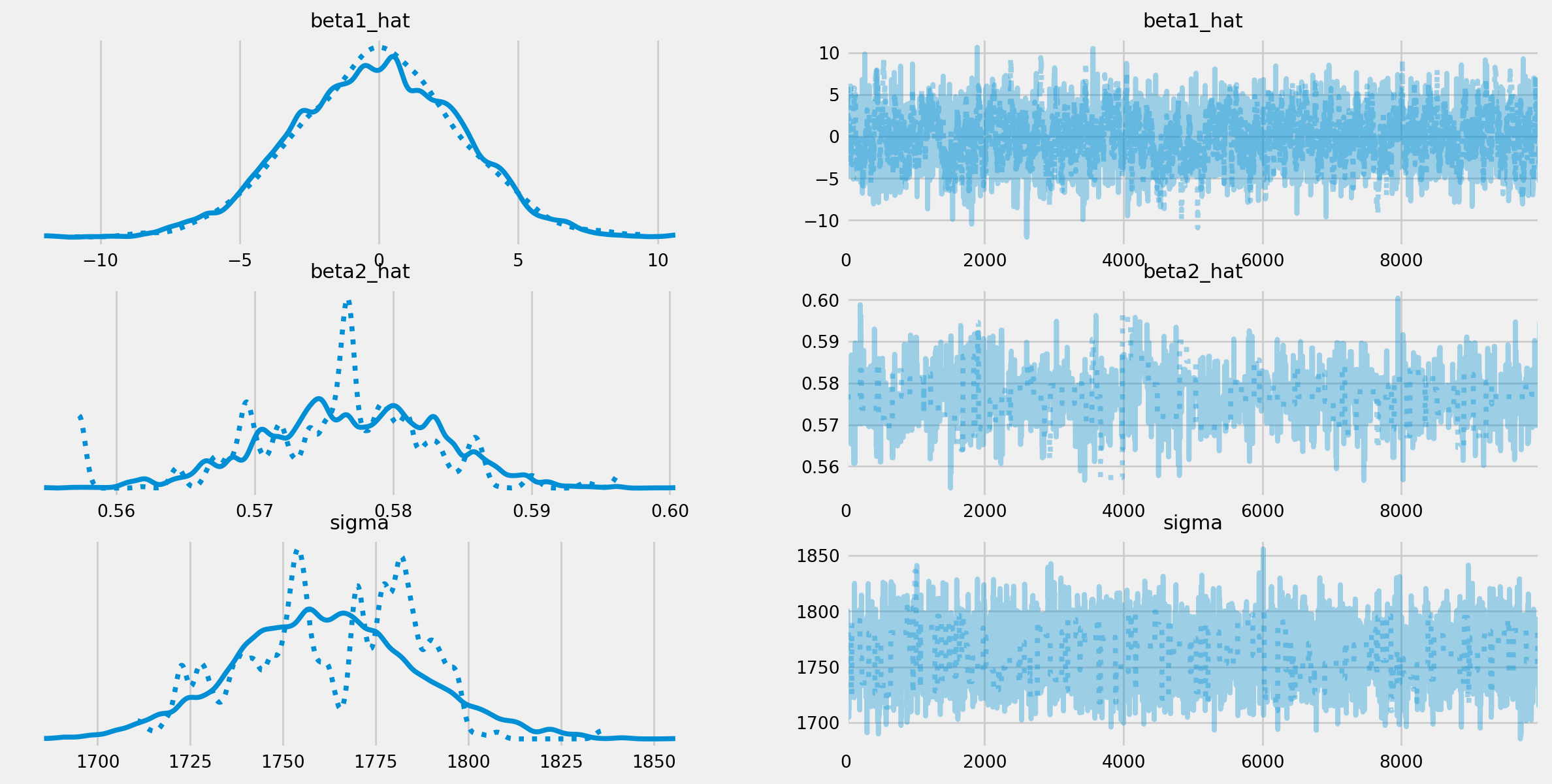
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Sequential sampling (2 chains in 1 job)
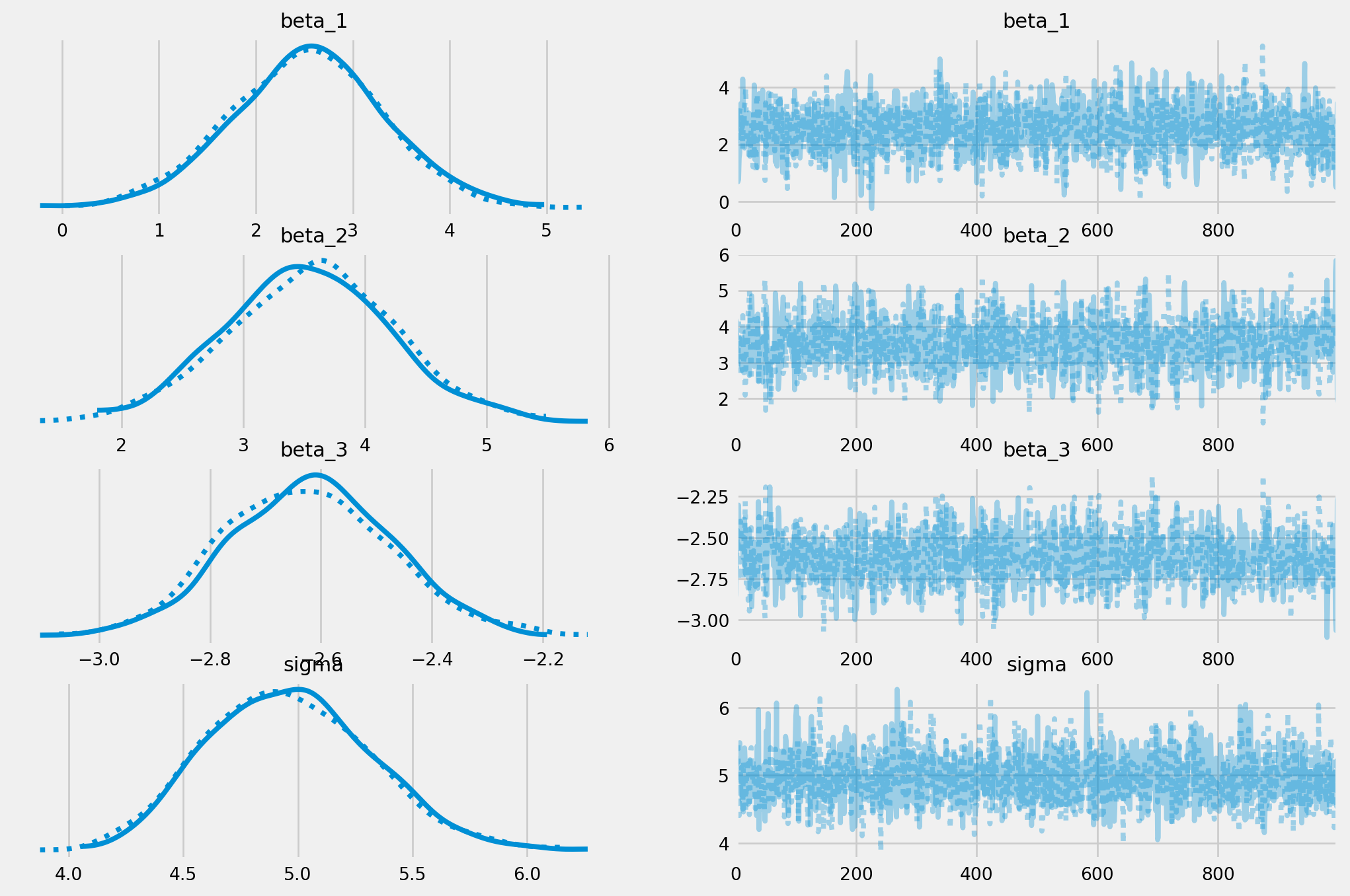
NUTS: [beta_1, beta_2, beta_3, sigma]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 11 seconds.
We recommend running at least 4 chains for robust computation of convergence diagnostics